Canonicalization is the cornerstone of clean indexing and healthy crawl budgets. In the complex world of modern websites, where pages are dynamically generated, URLs include parameters, and content syndication is common, duplicate content can quietly erode SEO equity. Without proper canonicalization, you risk diluting ranking signals, wasting crawl resources, and confusing search engines about your content’s authority.
In this article, we’ll demystify canonical tags, explore advanced strategies for managing duplicate content across domains and CMSs, and provide a tactical playbook for maintaining a unified, high-authority content structure. This is especially crucial for enterprise sites, ecommerce platforms, content marketers, and anyone publishing at scale.
For a broader technical SEO perspective, read our Technical SEO Audit guide.
What Is Duplicate Content in SEO?
Duplicate content refers to substantive blocks of content that appear across multiple URLs, either within the same domain or across different websites. Google does not penalize duplicate content by default, but it can:
- Dilute link equity across versions
- Split ranking signals
- Confuse Googlebot on which version to index
- Reduce the likelihood of showing rich features or canonical URLs
Types of Duplicate Content
- Exact duplicates: Same content duplicated across different URLs with no variation.
- Near-duplicates: Content that differs slightly due to product descriptions, geolocation, or CMS-generated copy.
- Boilerplate repetition: Headers, footers, and legal disclaimers copied across multiple templates.
- Scraped or syndicated content: When your original content is republished on other sites or networks.
- Localized variants: Pages that share content but differ only by region (e.g.,
/us/productvs/uk/product).
How Google Handles Duplicate Content
Google doesn’t outright penalize duplicate content, but their algorithms choose a canonical version algorithmically when a site doesn’t declare one. This may not always align with your intended content strategy. Therefore, actively managing canonicalization is the best way to preserve SEO value and user intent.
To understand how duplicate content affects indexation, check our Crawlability vs Indexability article.
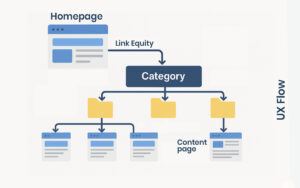
What Is Canonicalization?
Canonicalization is the process of selecting the preferred version of a set of duplicate or similar pages to be indexed by search engines. This is typically managed using the <link rel="canonical"> tag in the HTML <head>.
The Canonical Tag Tells Google:
“This is the original or authoritative version of the content. Index this one.”
Other tools that influence canonical signals include:
- HTTP headers (x-canonical)
- Sitemaps and robots.txt
- Internal linking structure
- Redirects (301s)
- hreflang annotations for internationalization
Canonical Tags vs 301 Redirects
- Use 301 redirects when you want to permanently move content and consolidate authority to one URL.
- Use canonical tags when multiple similar URLs need to exist but only one should be prioritized for indexing.
Why Canonicalization Matters for SEO
Ranking Signal Consolidation
Without a canonical, Google might index several versions of the same page, splitting backlinks, CTR, and user engagement data across them. Over time, this weakens the page’s ability to compete in search.
Crawl Budget Efficiency
Every site has a crawl budget—the number of pages Googlebot is willing to crawl during a session. Duplicate content wastes crawl budget, delaying the indexing of your most valuable content.
Preventing Index Bloat
Index bloat refers to the accumulation of low-value or duplicate URLs in Google’s index. This can lower your site’s perceived authority and impair performance tracking in Google Search Console.
Enhancing Content Authority
Clear canonical paths help Google assign authority and relevancy to the correct version—vital for E-E-A-T, featured snippet eligibility, and Knowledge Panel inclusion.
Reducing Internal Competition
Without proper canonicalization, two or more similar pages may compete for the same keyword, diluting rankings—an issue known as keyword cannibalization.
To learn more about dealing with these metrics, see our Core Web Vitals SEO Guide.
Common Causes of Duplicate Content
- URL Parameters: Sorting, filtering, and tracking (e.g.,
?utm_source=newsletter) often create duplicate pages. - Session IDs: Generated dynamically for cart sessions or user login.
- WWW vs Non-WWW / HTTP vs HTTPS: These small variations can be treated as separate pages if not redirected or canonically declared.
- Pagination Without Canonicals: Paginated content like
/blog?page=2should be handled with rel=”next”/rel=”prev” or canonicalized appropriately. - Mobile Versions: If your mobile and desktop sites use separate URLs, canonicalization and alternate tags are necessary.
- Printer-Friendly Versions: If they exist without canonical tags, they can be indexed and considered duplicates.
- Product Variants: Ecommerce stores often use separate URLs for size, color, etc., leading to content similarity.
- Syndicated or Republished Content: Especially for publishers sharing the same article across different sites.
- Staging or Test Environments: Indexed development URLs can quickly become a duplicate content nightmare.
- Indexable Faceted Navigation: Filtering options in ecommerce sites often generate thousands of low-value duplicate URLs.
Best Practices for Canonicalization
Use <link rel="canonical"> Consistently
Every page should declare a self-referencing canonical unless pointing explicitly to another canonical version. This helps establish consistent signals.
Avoid Conflicting Signals
Your canonical tag should match what is declared in:
- XML sitemaps
- HTTP headers
- Internal links
- hreflang and international targeting
- Open Graph tags (when syndicating)
Syndicate Content Carefully
When syndicating your content:
- Require the partner to add a canonical tag back to your original URL.
- Or request they use a
meta name="robots" content="noindex, follow"directive. - Provide canonical-compliant embed codes if you’re sharing tools or widgets.
Avoid Canonical Chains and Loops
Never have canonical tags that point to a URL that redirects or itself has a different canonical tag. Keep the chain direct: A → B, not A → B → C.
Optimize CMS Settings
Many CMS platforms generate duplicate pages by default. Configure them to:
- Generate clean, SEO-friendly URLs
- Avoid duplicate category/tag/author archives
- Prevent indexing of internal search results and thin pages
- Use canonical tags on paginated pages or disable them where necessary
Manage Parameterized URLs
Handle with server logic, canonical tags, or GSC parameter settings. Prefer canonical tags for better transparency and flexibility.
Advanced Strategies for Enterprise and Ecommerce SEO
- Cross-Domain Canonicals: Syndicating across multiple brand domains? Use canonical tags pointing to the original URL—even if it’s on a different domain.
- hreflang + Canonical Harmony: Use hreflang to differentiate localized content, and canonical to consolidate same-language duplicate URLs.
- Faceted Navigation Handling:
- Canonical to the base category page
- Block deep parameter paths with
robots.txtornoindex - Use AJAX for filters when possible
- Canonical + Noindex: While not standard, in some edge cases (like cloned testing environments), pairing canonicals with
noindexcan avoid unwanted indexing. - Paginated Content Handling:
- If each page is valuable, self-canonicalize and use rel=”next”/”prev” tags
- If content is thin, consider canonicalizing all to page 1
- AMP Pages: Always include
rel="canonical"from AMP to the original non-AMP version.
Tools to Audit Canonicalization & Duplicate Content
- Screaming Frog SEO Spider: Crawl your site to detect missing, incorrect, or conflicting canonical tags.
- Ahrefs Site Audit: Identify duplicate content, thin content, and canonical tag conflicts.
- Google Search Console:
- Use the URL Inspection tool to see canonical versions
- Check the Coverage report for “Duplicate without user-selected canonical”
- ZentroAudit and ZentroFix: If you’re using ZentroSEO, these modules flag non-canonical content and suggest automatic fixes.
- Sitebulb: Great for visualizing duplicate clusters and internal linking implications.
Canonical Tags and Structured Data
Combining canonical tags with structured data improves your site’s semantic footprint. Examples:
- If a page has
Productschema and points to a canonical, ensure the canonical URL also includes matching schema. - For articles, ensure the
author,datePublished, andheadlinein the schema reflect the canonical version. - Use
mainEntityOfPageto align content identity.
Final Thoughts
Canonicalization isn’t just a technical SEO fix; it’s a foundational practice for preserving authority, reducing noise, and signaling clarity to search engines. Whether you’re managing 10 or 10,000 URLs, mastering canonicalization will tighten your index, strengthen your content hierarchy, and protect your organic reach.
In an era where search engines use AI, entity understanding, and semantic signals to rank content, duplicate content is more than a crawl issue; it’s a topical authority issue. Poor canonicalization sends mixed signals that weaken your site’s standing across the board.
For ecommerce sites, content publishers, and platforms operating across multiple domains or languages, getting canonicalization right is non-negotiable.
Avoid cannibalization. Prevent index bloat. Keep your site clean.
Canonicalize with purpose. Audit frequently. And let your most important content shine through with clarity.